
Data For Equity Part 2: Using Existing Data Creatively and Creating New Data

In part 1 of our Data for Equity Series, we wrote about how meaningful access to good-quality local data is a key tool for health equity. In many communities, especially rural ones, the data needed to improve health equity simply does not exist. Or, if it does exist, it’s not meaningfully accessible to the people who need it. That’s why so much of our work at RHI is helping communities build better infrastructure for collecting and using local data. Sometimes that means finding existing data and storing, organizing, pairing, and sharing it differently so that it can actually be used. Sometimes that means creating entirely new data sets with tools like surveys or operational systems.
(Re)Structuring Existing Data
It’s easier and quicker to use existing data, so that’s usually where we start. However, some existing data isn’t organized in a way that we can work with. So, even if the relevant information exists, it might not be a usable dataset yet. While there are many valuable and well structured data sets out there, we sometimes have to do some extra work to transform unstructured information into a usable dataset.
Structuring and contextualizing public data makes it usable to community members
While we might not always have the specific data we need, there is no shortage of data overall. Thanks to increasing digitization, nearly everything we do produces data: signing up for an app, applying for a public benefit program, streaming a TV show are all activities that feed into large data sets. So many commonplace government processes produce datasets that are publicly available, even if they’re buried in government archives.
For instance, many people don’t know that New York State publicly archives massive data sets with extensive information about every parcel of land in the state, including construction date, owner(s), and the size and shape of the parcel. That’s information that could be used for countless purposes, but largely just sits on state servers. As part of a lead poisoning prevention program in Cortland, we used this dataset to build a tool to check the age of your home. We moved this public parcel data into a database and built a publicly-facing interface. Community members can enter their address, and the database tool shows them what year their home was built in. Based on that (and when lead paint was banned) it then gives them information about the likelihood that their home has lead paint and strategies and resources to minimize risk. This is public data–the construction year of parcels in the county. We’re making it more accessible by narrowing down the use-cases for the data rather than just sharing a giant, open-ended spreadsheet. We also put this tool on a webpage focused on lead poisoning prevention education and resources; we plan to run public health communications campaigns pointing community members to this webpage. We’re making the data more actionable by explicitly tying it to specific risk factors and ways to mitigate those risks. We link directly to local resources for lead testing and for nutrition assistance (good nutrition helps mitigate the impact of lead poisoning).
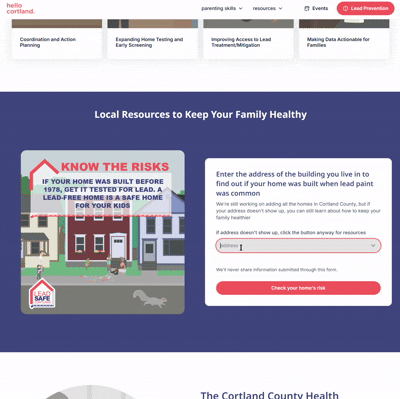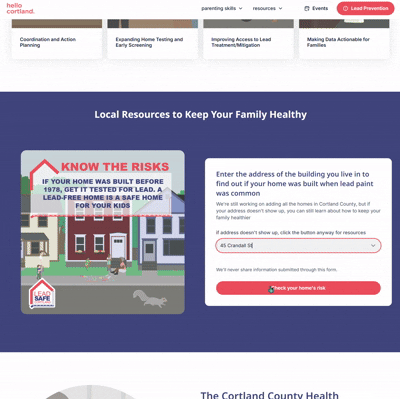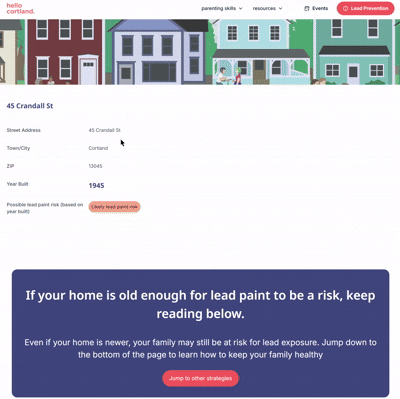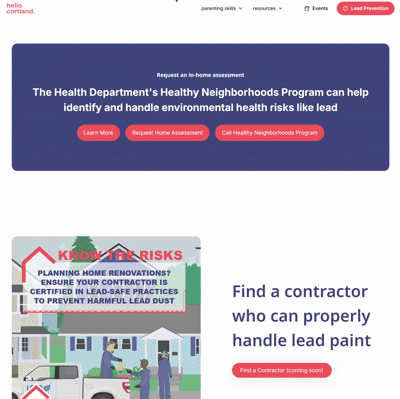
Consolidated directories of local resources remove barriers to accessing existing data
We have built several database tools in the form of directories. There is a lot of information available online about local programs and resources. But more often than not, that information is spread across several different agencies’ websites, making it hard to get a complete picture of the options available, let alone figure out the best fit for your needs. We’ve built directories that pull together information about similar programs (e.g. mental health resources, early childhood development and literacy resources) in one, consolidated place. This way, community members only have to visit one site to understand what local resources exist. We even tried to make it as easy as possible to connect with these resources from our directories by adding buttons that open the phone app to call programs with phone numbers, for instance.
By structuring this publicly available but unstructured data, we’ve made it more meaningfully accessible and more likely to be used by the people it’s relevant to.

Combining datasets gives us a fuller picture of local needs
In 2024, we conducted a landscape analysis for the Cortland County Housing and Homelessness Coalition. There was limited local data about housing and homelessness through sources tied directly to those things. We had things like the Point-in-Time Count and some information from local partners that provide housing-related services. We were able to combine this information with data from other sources that someone looking for housing data might not think to explore. For instance, we got (publicly available) data from Seven Valleys Health Coalition (which runs Cortland’s 211 program) about calls related to housing assistance. We also used data from the NYS Education Department about youth homelessness.
Creating New Datasets
When we can use existing data sets, we’ll try to do that–even if it means more work to (re)structure them to be more useful. However, sometimes the data we need to answer a certain question or make a certain decision does not exist yet. In those cases, we find ways to collect new data and build new datasets.
The way we have built the annual Youth Survey lets us see a variety of needs that would be hard to see otherwise
Every year since 2002, RHI has surveyed 7th-12th grade students in Cortland County about substance use behaviors and risk and protective factors that predict adolescent problem behaviors using the validated survey tool: New York State PFS Youth Survey. Starting with the 2023-2024 school year, we are using a new survey instrument. We developed this new survey to better match the evolving needs of youth in rural New York: substance use rates were declining and staying low overall, but there were still some populations with worse indicators and other kinds of issues. The new survey is focused on more holistic health behaviors and social drivers of health, not just substance use prevention. We collect population-level data about suicide prevention indicators, mental healthcare access, physical and environmental health indicators, adverse childhood experiences, and social determinants of health.

Far too often, data collection systems get siloed into one project or department (usually because of where the underlying funding came from). It’s important to us to think of datasets in a broader and more interconnected way. Youth substance use has never been completely isolated from these other factors, and collecting data from the same group about different kinds of health factors means that we can see some of those intersectional correlations and then, crucially, use our sometimes limited resources strategically.
Importantly, we also ask more and more detailed demographic questions than what’s in the PFS Youth Survey we started with. For instance, we ask about race, ethnicity, gender identity, sexual orientation, and disability–all with granular response options that let us see more nuanced trends and disparities. We work with partners to understand the local resources and to use this data to optimize efforts at closing those disparities, tailoring interventions to counteract minority stress and move toward health equity.
Without robust data infrastructure, many communities use national data to inform their local priorities and policies. Local data is crucial for appropriately responding to local needs. Data that allows us to see disparities appears to be increasingly difficult to access at a national level, due to the Trump Administration’s restrictions around DEI, which means that it is more important than ever to collect and use local data that includes information about marginalized groups. Accurate, detailed, and place-based data about the health disparities in a community is a crucial step to inform local health equity work, especially now.=
We have worked with Cortland County to set up this important data collection and use infrastructure and are now talking with other communities to expand it. We know that many rural communities don’t have the resources or expertise to start this kind of project, so we are working on finding ways to make the Youth Survey infrastructure less expensive (another version of accessibility) and more scalable.
Systems built to support program operations and reporting can also collect datasets to inform need and program improvement
From November 2024 to April 2025, RHI and other community partners operated a low-threshold daytime resource center for people experiencing housing insecurity and homelessness. This center--the Grace Space--was housed at Grace and Holy Spirit Church in downtown Cortland. We built digital systems in-house (using Airtable, a no-code relational database tool) to support the operation of the center as well as collect data about needs, services, and guest demographics. That means we were able to learn a lot about how to do this effectively through implementing the pilot and learn a lot about the experiences and needs of people experiencing homelessness locally. We even accomplished our goal of creating a real-name database of people who need housing support. Between February 4th and April 30th, we served 253 unique individuals, two-thirds of whom were over 35; 33.8% were 45 years old or older. All but 4 individuals who used the Grace Space over the winter identified as having some kind of disability.

These systems started out relatively simply, with just a digital check-in form. As the season went on, we expanded this operational system to help manage the use of the showers, the storage bins we offered guests, and feedback from guest and visiting outreach workers. We started an NYS-DOH-funded Harm Reduction project during the run of the Grace Space. This project required us to collect and report certain information about our clients’ demographics, the services we delivered, and the referrals we made. We were able to build this into our existing operational systems in ways that minimized staff burden (since they were already using these systems) and expand on the required data collection (since we had to report to the state). We were able to easily add additional fields that weren’t required for reporting but helped us improve service delivery, better understand the needs of our clients, and, later on, make a case for continued support for the Grace Space as a whole.
We followed a human-centered approach to build a system that met multiple of our needs, was just as usable for our data and our direct service staff, and was flexible enough to be implemented quickly and updated on the fly. Responsive, integrated digital systems like this allow us to piggyback data collection off of service delivery work that would happen regardless of the data infrastructure.
Local Data Drives Local Impact
Local data was made from the lives of local people; real people. Your local data is one way you have a voice in your community. But again, that data is often hard to access, hard to use, or not being collected at all. One of the most common barriers for data-driven health equity work in rural communities is that good-quality, relevant data often doesn’t exist, or, if it does, it’s spread across disparate websites or archives. Good, local data is a health equity issue [link to Ashley’s article]. It allows communities to prioritize and respond based on the actual conditions they face, rather than based on national trends or proxy measures. Often, that means community leaders or specific organizations using data to drive priorities. However, it can also mean individual community members or groups using data to validate their experiences.
(Re)structuring data collection to include more people, more experiences, and more disparities means more ways for our community members to find themselves represented in local data. More ways to be represented means more ways for a person’s voice to factor into local decision-making by default, at least in theory. In practice, the availability and accessibility of data does not always mean it gets used.
That’s why it’s crucial for us to not just publish data sets but to empower community members to use the data–use their representation–to advocate to community leaders. It’s easy to ignore one voice as an outlier. It’s harder to ignore the collective voice of people with shared experiences. It’s even harder to ignore when those experiences are tied to robust, current local data.
Promoting health equity goes further than delivering programs; it's also about ensuring communities have the power to understand and address the factors that influence their health. Without good-quality local data, inequities stay invisible and resources risk being misdirected. We say that (re)structuring existing data and creating new data sets are two of RHI’s tools for health equity. By that, we mean that these are key ways that we try to empower communities to use data to understand their experiences and advocate for their needs.
We make this data available to community leaders, to service providers, and to the general public. By building systems that make existing data usable and create new data where gaps exist, we can give communities the tools to see where the disparities lie and hold institutions accountable in their progress. That is, we can give community members and organizations tools to work toward health equity themselves. When the right information is in the right hands, it can go past data and become a driver of health equity.
This article is part 2 of our series Data for Equity.